

Text Extractor - Extract text from PDF & Image with OCR
Text Extractor helps you turn scanned PDF documents, digital images into searchable and editable text content. It can eliminate your retyping effort by the advanced OCR (Optical character recognition) technology, which can recognize text from image accurately and extract text content efficiently.
**Free demo version is available on our official website**
Key Features:
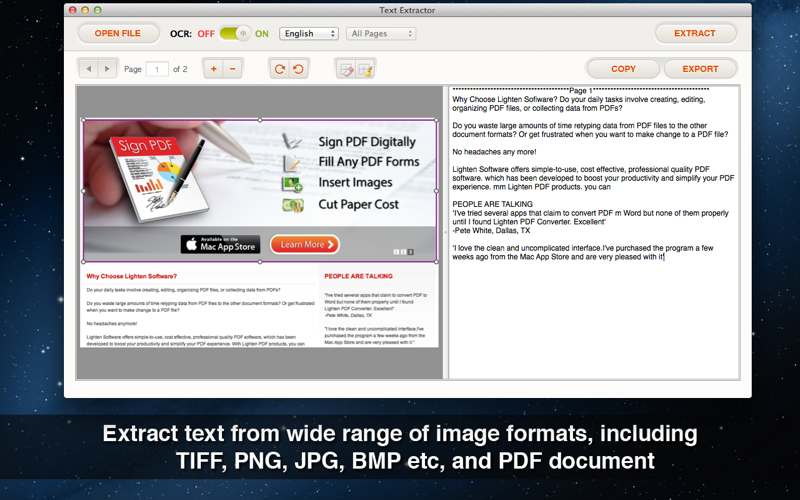
* Convert PDF and image into searchable and editable text content
Its frustrated if you got an scanned PDF or image file, youll have to retype them over manually if you want to get the information. With Text Extractor, you can unlock text content, easily get and use the information locked in PDF files.
* Advanced OCR Feature
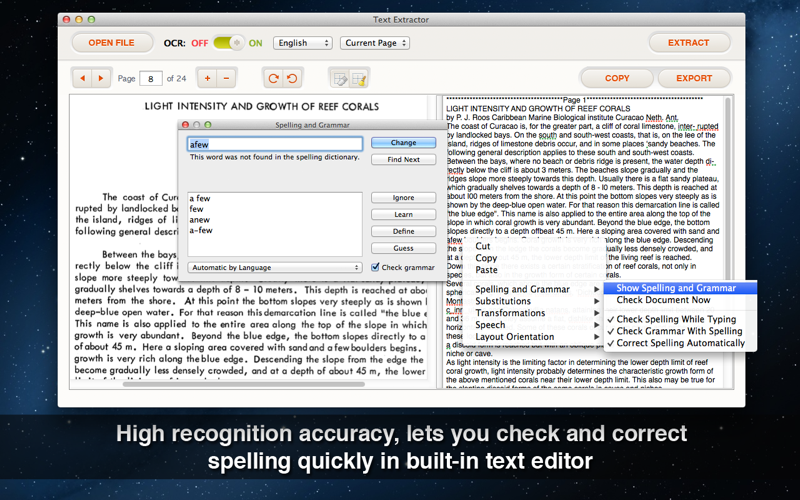
When you scan a paper document and save it as PDF or image file, actually the whole content will be captured as image instead of text and font information, OCR tech is used for text recognition. Accuracy is the core of an OCR app, Text Extracts recognition accuracy can reach up to 90% if the source file has high quality. Save your time from correcting error after conversion.
* Intuitive interface, easy-to-use
OCR conversion is not an easy task, but with the easy-to-use interface, you can finish extraction in fewer steps.
1. Open a PDF or image file,
2. Select document language,
3. Click Extract button to start OCR recognition,
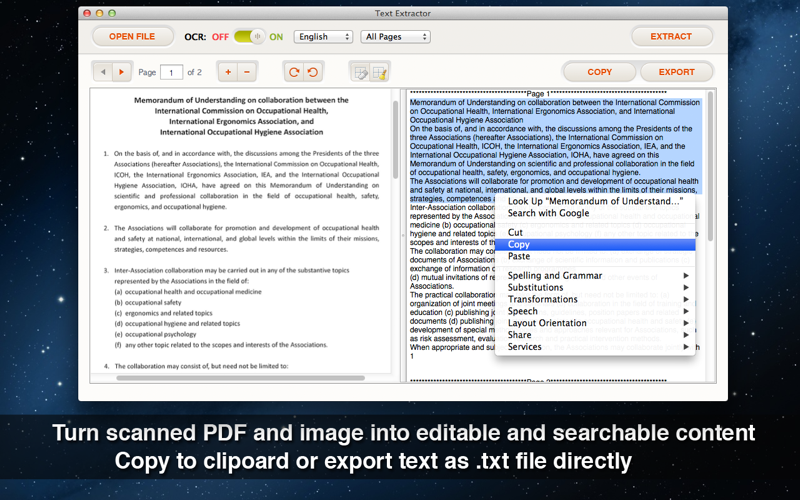
4. Done, you can copy the text to clipboard or export it as .txt file.
* Wide Range of Supported Languages
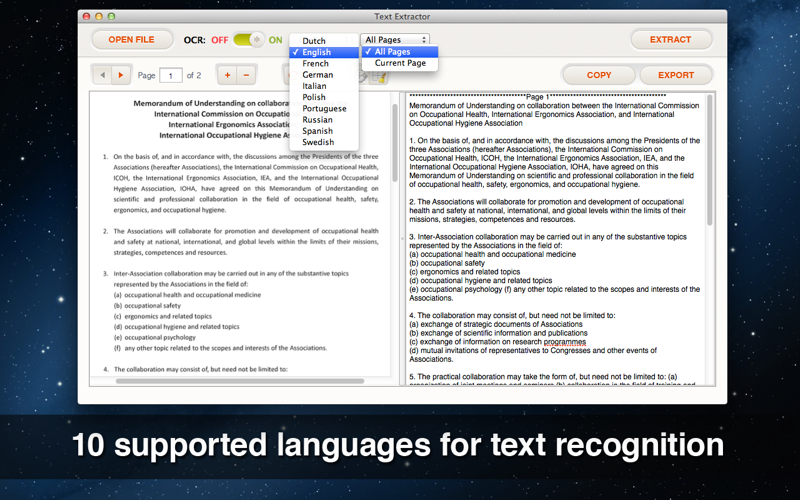
Text Extract can detect 10 languages, including English, French, German, Italian, Swedish, Russian, Polish, Dutch, Spanish, Portuguese.
* Efficient Conversion At Greater Speed
Text Extractor efficiently converts large PDF documents and images into editable and searchable text, and deliver the converted text content faster. If OCR is not enabled, it takes less than 1 sec to extract each page.
And it lets you edit and modify the extracted text content directly in the built-in text editor, you can copy the content into clipboard and export as plain text (.txt).
* Here are something you can do for improving OCR results:
- Please increase the resolution to 300 dpi for standard printed text, and higher for small font,
- Rotate the page to the correct orientation before performing OCR.
- Choose the correct document language,
- Select the areas you dont want to extract can increase conversion accuracy and efficiency, such as image and charts etc.
If you have any questions or feedback, please do not hesitate to contact our support team via [email protected], thanks!